hadoop介紹
hadoop為一個雲端運算框架.
在雲端的分類中,hadoop屬於PaaS(Platform as a Service), 也就是說hadoop在雲端上提供一個運算的框架,提供使用者計算模型與資料儲存, 方便使用者直接存取大量分散式的虛擬機資源.
hadoop一共提供兩種服務, 一個是分散式的資料儲存(HDFS, hadoop distributed file system), 另一種則是基於HDFS的平行運算架構,MapReduce. 在接下來的文章中, 我們將非常簡短的介紹一下HDFS和MapReduce.
hadoop以主從式(master-slave)的分散式存取架構提供一個叢集的管理. 所謂主從式架構, 就是指在叢集中, 有一個主要節點(master)和多個從屬節點(slave)進行叢集的運算. 主要節點通常負責叢集的管理, 而次要節點則負責叢集的運算. 對於主從式架構而言, 好處是架構清晰容易設計資料交換的方法, 壞處則是當主要節點出問題時, 將導致叢集的失效.
在雲端的分類中,hadoop屬於PaaS(Platform as a Service), 也就是說hadoop在雲端上提供一個運算的框架,提供使用者計算模型與資料儲存, 方便使用者直接存取大量分散式的虛擬機資源.
hadoop一共提供兩種服務, 一個是分散式的資料儲存(HDFS, hadoop distributed file system), 另一種則是基於HDFS的平行運算架構,MapReduce. 在接下來的文章中, 我們將非常簡短的介紹一下HDFS和MapReduce.
hadoop以主從式(master-slave)的分散式存取架構提供一個叢集的管理. 所謂主從式架構, 就是指在叢集中, 有一個主要節點(master)和多個從屬節點(slave)進行叢集的運算. 主要節點通常負責叢集的管理, 而次要節點則負責叢集的運算. 對於主從式架構而言, 好處是架構清晰容易設計資料交換的方法, 壞處則是當主要節點出問題時, 將導致叢集的失效.
以資料儲存而言, 在HDFS的架構下, 每一筆資料都有多個備份(預設為3份), 分散儲存於各節點.
當新的HDFS資料產生後, 由主控節點(Name Node)要求資料節點(Data Node)備份原有資料, 自動產生備份檔隨機存取於其他資料節點並遣維護在各從屬節點上的備份, 在資料損毀時, 主控節點也提供自動重新備份的服務, 以確保雲端上資料的安全性.

為了減輕主控節點的負擔, 在hadoop中, 主控節點只負責目錄(Metadata)資料的儲存. 當使用者向HDFS要求一份資料時, 主控節點告訴使用者資料在哪一個資料節點, 而後續的資料查詢和傳輸,則由使用者和資料節點直接溝通.
MapReduce則是為了這樣特殊hadoop的儲存架構所設計的程式框架. 考慮到hadoop伊開始設計時希望服務TeraByte, 甚至是PetaByte的資料量, 搬移資料變成沉重的負擔, 因此, MapReduce搬移程式到資料節點上, 進行運算(Map), 並把各節點上的運算結果集結(Reduce), 而得到最終的運運結果.

在MapReduce中, 最為知名的範例為Word Count, 就是利用分散式的架構, 平行處理每個文件片段的字數統計, 並把結果統合而得到最終文件的字數統計資料. MapReduce的程式架構可以分成兩個部分, 一部分是Mapper, 另外一部分是Reduder.
Mapper主要的功用是把已經由Hadoop分散式文件系統拆成許多小塊的資料, 經由索引值(Key)的分類, 進行平行而且相同的處理. Mapper的輸出經過重新排程的動作之後產生新的索引值, 並據此傳給不同的Reducer. 每個Recuder把收集到的資料做處理之後結合在一起, 最後輸出整體結果.
MapReduce運算架構的優點是, 在找到演算法中的獨立處理項次後, 我們藉由簡單的資料分割以及傳送, 就可以在Hadoop平台上完成平行化的進程. 然而, 由於MapReduce是一種始於硬碟, 終於硬碟的運算架構, 並不適合進行迭代的運算, 同時, MapReduce過程中, 將對於整個叢集進行操作, 以計算框架而言, 缺乏彈性, 難以擴展到多樣的演算法需求.
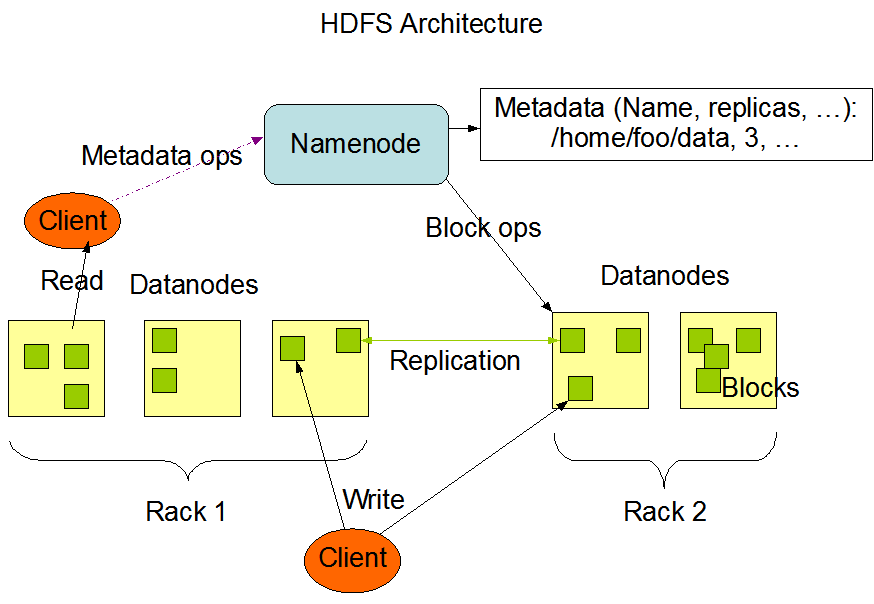
為了減輕主控節點的負擔, 在hadoop中, 主控節點只負責目錄(Metadata)資料的儲存. 當使用者向HDFS要求一份資料時, 主控節點告訴使用者資料在哪一個資料節點, 而後續的資料查詢和傳輸,則由使用者和資料節點直接溝通.
MapReduce則是為了這樣特殊hadoop的儲存架構所設計的程式框架. 考慮到hadoop伊開始設計時希望服務TeraByte, 甚至是PetaByte的資料量, 搬移資料變成沉重的負擔, 因此, MapReduce搬移程式到資料節點上, 進行運算(Map), 並把各節點上的運算結果集結(Reduce), 而得到最終的運運結果.
MapReduce的系統架構(來自Dean和Ghemawat的論文)
在MapReduce中, 最為知名的範例為Word Count, 就是利用分散式的架構, 平行處理每個文件片段的字數統計, 並把結果統合而得到最終文件的字數統計資料. MapReduce的程式架構可以分成兩個部分, 一部分是Mapper, 另外一部分是Reduder.
Mapper主要的功用是把已經由Hadoop分散式文件系統拆成許多小塊的資料, 經由索引值(Key)的分類, 進行平行而且相同的處理. Mapper的輸出經過重新排程的動作之後產生新的索引值, 並據此傳給不同的Reducer. 每個Recuder把收集到的資料做處理之後結合在一起, 最後輸出整體結果.
MapReduce運算架構的優點是, 在找到演算法中的獨立處理項次後, 我們藉由簡單的資料分割以及傳送, 就可以在Hadoop平台上完成平行化的進程. 然而, 由於MapReduce是一種始於硬碟, 終於硬碟的運算架構, 並不適合進行迭代的運算, 同時, MapReduce過程中, 將對於整個叢集進行操作, 以計算框架而言, 缺乏彈性, 難以擴展到多樣的演算法需求.


留言
張貼留言