hbase java api 介紹 (2)
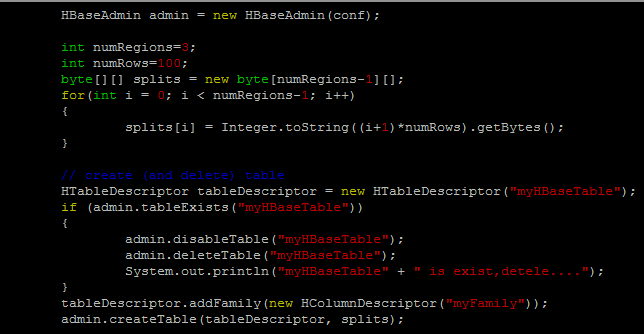
在很久以前的hbase java api介紹 (1)之後, 今天總算找時間寫了第二篇內容, 在此篇文章中, 將會敘述比較正規的java client寫作方式, 增進讀取hbase的效率, 以下是範例程式: import java.io.*; import java.net.*; import java.util.*; import java.lang.*; import org.apache.hadoop.hbase.*; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.util.*; import org.apache.hadoop.conf.Configuration; public class hbasetest2 { public static Configuration conf; static { conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.property.clientPort", "2222"); conf.set("hbase.zookeeper.quorum", "master,slave01,slave02"); conf.set("hbase.master", "master:600000"); } static public void main(String[] args) throws Exception { String[] Tab...