hbase split function (1)
在hbase中, 表格被切隔成不同大小的Region,
不同的Region存放於不同的RegionServer上.
Region的數量將影響LoadBalancer的運行結果,
同時考慮到每個RegionServer上有限的記憶體資源,
如何依據表格以及RegionServer的資源, 動態的切割表格成為Region,
是HBase規畫的重要問題。
一般而言, 一個RegionServer上可以服務約數十個Region.
舉例來說, 考慮到一個RegionServer的HeapSize是2 GB, MemStore參數是0.4,
此時, FlushSize是128MB, 若是把所有RegionServer資源用來服務一個表格,
能夠最多服務約6個column family, 假設每一筆資料大小是1個Byte,
記憶體中則可以暫存約128000筆數值.
當表格資料量(HStoreFile)超出Region所限制的大小時, Region會自動切割成兩個Region,
此參數設定如下,預設為10GB:
<property>
<name>hbase.hregion.max.filesize</name>
<value>10737418240</value>
</property>
由於, 避免產生過多的Regions,
也可以設定hbase中Region數目的最大值,預設為int_max:
<property>
<name>hbase.regionserver.regionSplitLimit</name>
<value>2147483647</value>
</property>
當Region進行切割時, 會有一段資料搬移的時間,
造成表格暫時下線(offline), 無法被存取,
對於即時的資料輸入來說, 這段時間將造成資料處理的延遲.
為了增進HBase中存取的效率, 在創建表格時,
應該根據鍵值(row key)的規律性來預先切割表格成為多個Region,
舉例而言, 我們先依據鍵值把myHBaseTable在100和200切開,
分成三個不同的Region, 以Java的程式表示如下:
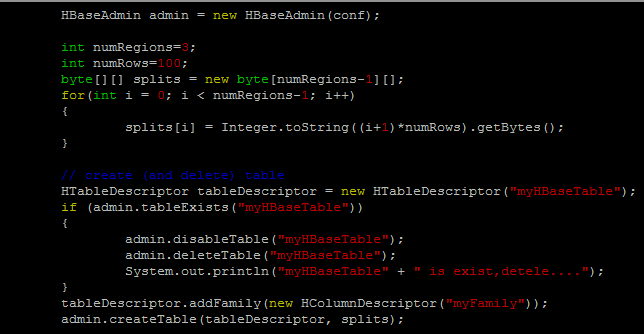
隨著資料的進入, 我們也可以預先切割出新的Region,
例如, 把鍵值300的地方作為分界, 切割出新的Region, Java程式如下:

在進行hbase Region切割時需要注意,
在hbase中編碼的方式是採取字典編碼(dictionary indexing), 舉例來說,
一串數字{1, 2, 3, 10, 22, 30, 100}在HBase當中的順序是{1, 10, 100, 2, 22, 3, 30}.
因此, 在鍵值(row key)的設計上就必須特別注意, 必須和HBase編碼的機制相襯,
才能夠有效的利用Region分割的方式, 將儲存資料分散於多個Region中.
不同的Region存放於不同的RegionServer上.
Region的數量將影響LoadBalancer的運行結果,
同時考慮到每個RegionServer上有限的記憶體資源,
如何依據表格以及RegionServer的資源, 動態的切割表格成為Region,
是HBase規畫的重要問題。
一般而言, 一個RegionServer上可以服務約數十個Region.
舉例來說, 考慮到一個RegionServer的HeapSize是2 GB, MemStore參數是0.4,
此時, FlushSize是128MB, 若是把所有RegionServer資源用來服務一個表格,
能夠最多服務約6個column family, 假設每一筆資料大小是1個Byte,
記憶體中則可以暫存約128000筆數值.
當表格資料量(HStoreFile)超出Region所限制的大小時, Region會自動切割成兩個Region,
此參數設定如下,預設為10GB:
<property>
<name>hbase.hregion.max.filesize</name>
<value>10737418240</value>
</property>
由於, 避免產生過多的Regions,
也可以設定hbase中Region數目的最大值,預設為int_max:
<property>
<name>hbase.regionserver.regionSplitLimit</name>
<value>2147483647</value>
</property>
當Region進行切割時, 會有一段資料搬移的時間,
造成表格暫時下線(offline), 無法被存取,
對於即時的資料輸入來說, 這段時間將造成資料處理的延遲.
為了增進HBase中存取的效率, 在創建表格時,
應該根據鍵值(row key)的規律性來預先切割表格成為多個Region,
舉例而言, 我們先依據鍵值把myHBaseTable在100和200切開,
分成三個不同的Region, 以Java的程式表示如下:
隨著資料的進入, 我們也可以預先切割出新的Region,
例如, 把鍵值300的地方作為分界, 切割出新的Region, Java程式如下:
在進行hbase Region切割時需要注意,
在hbase中編碼的方式是採取字典編碼(dictionary indexing), 舉例來說,
一串數字{1, 2, 3, 10, 22, 30, 100}在HBase當中的順序是{1, 10, 100, 2, 22, 3, 30}.
因此, 在鍵值(row key)的設計上就必須特別注意, 必須和HBase編碼的機制相襯,
才能夠有效的利用Region分割的方式, 將儲存資料分散於多個Region中.


留言
張貼留言