[SPARK] MLlib 的使用 (2)
在使用MLlib的Linear Regression程式中,
我們大概可以簡單地分成以下三部分:
// Load training data
val training = spark.read.format("libsvm")
.load("data/mllib/sample_linear_regression_data.txt")
其目標是從檔案中, 取得數值並創立一個RDD,
此檔案依循libsvm的格式 (也就是key-value pair),
詳細的資料格式可以參考林智仁老師的網頁 (libsvm) 介紹:
https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/
至於Regression model的建立, 則是直接取用MLlib的函式庫,
程式碼如下:
val lr = new LinearRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
// Fit the model
val lrModel = lr.fit(training)
在程式中, lr是宣告的Linear Regression model,
該函式可以進一步參考Spark官方的說明: 連結
簡單來說, 放進去的參數用來決定遞迴的次數 (.setMaxIter(10)),
以及Cost function中的參數數值 (.setRegParam(0.3), .setElasticNetParam(0.8)),
而Cost function可以表示如下:
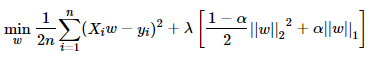
其中, .setRegParam(0.3)對應於\gamma,
.setElasticNetParam(0.8)對應於\alpha,
在確定模型後, 就放入資料開始進行運算: lrModel = lr.fit(training),
程式的最後, 則把學習得到的參數列出, 不再詳述,
值得注意的大概只有可以把資料儲存成RDD給之後程式使用,
綜合以上敘述, 在範例中的Linear Regression程式,
並沒有進行平行化處理, 而只是提供MLlib的程式方便執行,
(雖然說Linear Regression本身不支援平行化, 可能要看看其他演算法...)
若我們要設計平行化處理流程, 可能還是要從RDD的操作開始,
並利用Map等功能, 來進行數據處理間的平行化...
Note: 執行結果如下:
RMSE: 10.189077167598475
r2: 0.022861466913958184
我們大概可以簡單地分成以下三部分:
- 資料讀取
- Regression模型的建立
- 顯示計算結果
// Load training data
val training = spark.read.format("libsvm")
.load("data/mllib/sample_linear_regression_data.txt")
其目標是從檔案中, 取得數值並創立一個RDD,
此檔案依循libsvm的格式 (也就是key-value pair),
詳細的資料格式可以參考林智仁老師的網頁 (libsvm) 介紹:
https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/
至於Regression model的建立, 則是直接取用MLlib的函式庫,
程式碼如下:
val lr = new LinearRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
// Fit the model
val lrModel = lr.fit(training)
在程式中, lr是宣告的Linear Regression model,
該函式可以進一步參考Spark官方的說明: 連結
簡單來說, 放進去的參數用來決定遞迴的次數 (.setMaxIter(10)),
以及Cost function中的參數數值 (.setRegParam(0.3), .setElasticNetParam(0.8)),
而Cost function可以表示如下:

其中, .setRegParam(0.3)對應於\gamma,
.setElasticNetParam(0.8)對應於\alpha,
在確定模型後, 就放入資料開始進行運算: lrModel = lr.fit(training),
程式的最後, 則把學習得到的參數列出, 不再詳述,
值得注意的大概只有可以把資料儲存成RDD給之後程式使用,
綜合以上敘述, 在範例中的Linear Regression程式,
並沒有進行平行化處理, 而只是提供MLlib的程式方便執行,
(雖然說Linear Regression本身不支援平行化, 可能要看看其他演算法...)
若我們要設計平行化處理流程, 可能還是要從RDD的操作開始,
並利用Map等功能, 來進行數據處理間的平行化...
Note: 執行結果如下:
RMSE: 10.189077167598475
r2: 0.022861466913958184


留言
張貼留言