[SPARK] Spark Streaming (1)
對於雲端運算而言, 另一個問題是如何提供即時的資料處理,
在原本 hadoop 的架構下, 由於目標在處理大量的資料, 並不提供即時的資料運算,
然而, 隨著雲端運算的概念發展, 越來越多的應用需要及時結果,
因此, 也有許多平台 (如: Storm, Infosphere) 考慮了即時資料串流處理的方式,
簡單來說, 把輸入資料做為資料流, 把運算做為流節點,
提供透過各節點的處理, 可以把有用的資料留下, 作為放入儲存前的前處理,
對於此類流運算而言, 節點之間的同步成了最大的問題,
也常常是該運算架構中的瓶頸.
對於 Spark 來說, 流運算架構也基於前述的 RDD 資料結構,
而把所輸入的資料切為多個小型的 RDD, 並對每一個 RDD 進行運算,
如下圖所示:

相同的, Spark Streaming 也可以用 WordCount 來簡單作為範例,
如果只是為了 DEMO Spark Streaming 的功用, 我們可以輸入以下兩行程式:
第一個程式是 Spark Streaming 的範例,
該程式會透過監聽 port 為 9999 的 TCP 連線作為輸入,
建立 TCP 連線, 並可以輸入內容, 而運作之後結果如下:

在圖中, 我們可以看到左邊是WordCount的結果, 而右邊是輸入的內容,
在此範例中, 每一行輸入都會被單獨計算, 並和下一個時間的輸入互相獨立,
因此, 就算輸入相同的內容 ("hi"), 字數並不會累計,
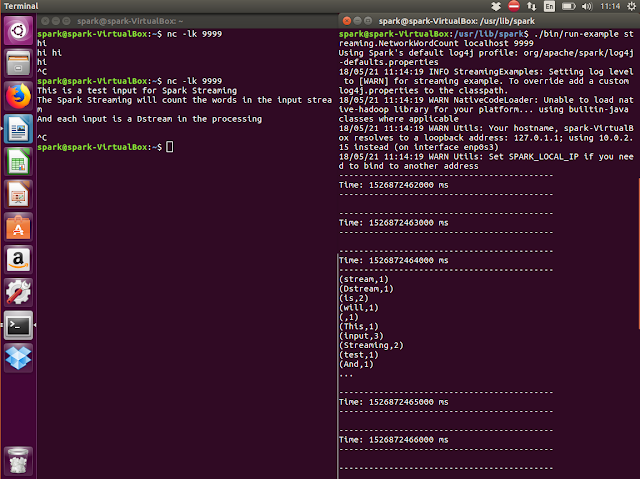
當然, 我們也可以一次輸入大量文字,
此時可以看到在每秒 (1000 ms) 的區間內產生大量的計數結果,
然而, 若是要對串流資訊做更好的處理,
就必須要考慮不同時間點計算結果之間的關聯性,
這也是之後要進一步探討的部分.
在原本 hadoop 的架構下, 由於目標在處理大量的資料, 並不提供即時的資料運算,
然而, 隨著雲端運算的概念發展, 越來越多的應用需要及時結果,
因此, 也有許多平台 (如: Storm, Infosphere) 考慮了即時資料串流處理的方式,
簡單來說, 把輸入資料做為資料流, 把運算做為流節點,
提供透過各節點的處理, 可以把有用的資料留下, 作為放入儲存前的前處理,
對於此類流運算而言, 節點之間的同步成了最大的問題,
也常常是該運算架構中的瓶頸.
對於 Spark 來說, 流運算架構也基於前述的 RDD 資料結構,
而把所輸入的資料切為多個小型的 RDD, 並對每一個 RDD 進行運算,
如下圖所示:

相同的, Spark Streaming 也可以用 WordCount 來簡單作為範例,
如果只是為了 DEMO Spark Streaming 的功用, 我們可以輸入以下兩行程式:
./bin/run-example streaming.NetworkWordCount localhost 9999第一個程式是 Spark Streaming 的範例,
該程式會透過監聽 port 為 9999 的 TCP 連線作為輸入,
$ nc -lk 9999建立 TCP 連線, 並可以輸入內容, 而運作之後結果如下:

在圖中, 我們可以看到左邊是WordCount的結果, 而右邊是輸入的內容,
在此範例中, 每一行輸入都會被單獨計算, 並和下一個時間的輸入互相獨立,
因此, 就算輸入相同的內容 ("hi"), 字數並不會累計,

當然, 我們也可以一次輸入大量文字,
此時可以看到在每秒 (1000 ms) 的區間內產生大量的計數結果,
然而, 若是要對串流資訊做更好的處理,
就必須要考慮不同時間點計算結果之間的關聯性,
這也是之後要進一步探討的部分.


留言
張貼留言