docker 介紹 (3-2): docker on OpenStack
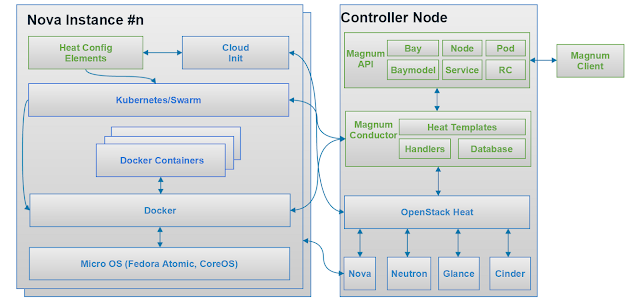
在OpenStack kilo版本中, 提出了Magnum的支援, 不同於前述的Heat和Nova嘗試在既有的架構下結合docker的方式, Magnum是一個通用的容器管理解決方案, 支援Kubernetes和Docker, Magnum為了結合既有的OpenStack支援, 以及docker特有的叢集(Swarm)部屬方式, 而擁有以下的特點[4]: Magnum在任何需要管理容器的地方, 使用其他的OpenStack元件, 例如: Nova, Heat, Neutron, Glance和Keystone Nova用於創建輕量的虛擬機(micro VM), docker容器在虛擬機中運行 Heat用於整體資源調度, 對於docker, Heat則會創建docker Swarm叢集以及Swarm Agent Magnum創建bay-model(叢集模型), bay(叢集)以及容器的創建


