[SPARK] MLlib 的使用 (2)
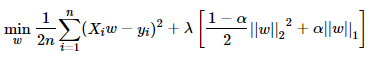
在使用MLlib的Linear Regression程式中, 我們大概可以簡單地分成以下三部分: 資料讀取 Regression模型的建立 顯示計算結果 在資料讀取部分, 對應於以下程式碼: // Load training data val training = spark.read.format( " libsvm " ) .load( " data/mllib/sample_linear_regression_data.txt " ) 其目標是從 檔案 中, 取得數值並創立一個RDD, 此檔案依循libsvm的格式 (也就是key-value pair), 詳細的資料格式可以參考林智仁老師的網頁 (libsvm) 介紹: https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/




