deep learning 新架構 (2): Google TensorFlow
然而, 真正讓deep learning衝擊人類信念的,
應該是Google Alpha Go和李世石的圍棋對弈,
2016年3月, Alpha Go以4比1擊敗世界棋王, 贏得圍棋的桂冠,
這背後的技術就是deep learning, 也是建立於這次介紹的TensorFlow,
TensorFlow是一套開源平台, 由Google Brain團隊設計開發,
https://www.tensorflow.org/
在網路上有許多資源, 甚至有中文的社群:
http://www.tensorfly.cn/
相較於CUDA, TensorFlowr提供了一套資源調配技術,
可以分配運算資源到CPU或是 (藉由CUDA driver存取的) GPU中運算,
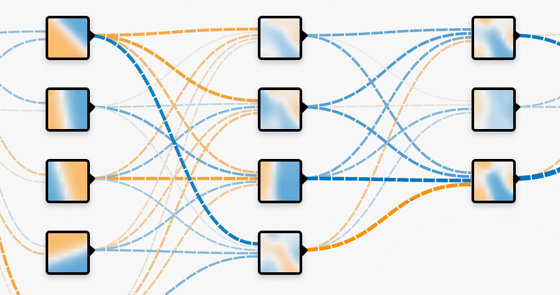
相對於傳統的deep learning運算方式, TensorFlow可以定義節點上更複雜的運算.
此時, 整個運算的框架, 更近似於傳統的HPC計算模式,
或者稱之為: Data Flow Graph
按照慣例, Google的開放資源永遠把最重要的技術隱藏起來,
其中, 第一點是TensorFlow的分散模式,
目前, TensorFlow仍只有單機模式, 調動的資源只有本機上的CPU和GPU,
可以視為一種單機內部自動資源配置的平行化架構,
然而, 對於一個複雜的運算而言, 例如圍棋,
如何協調單機和單機之間的資源配置, 是更困難的問題,
在一次Google研究員給的Talk中, 他們承認, 內部運行的是分散式架構,
只是這一部分的原始碼迄今尚未開放,
第二個隱藏起來的是稱為Tensor Processing Unit (TPU)的硬體,

從5月發佈到現在...短期內應該是不會商品化,
然而, 這對於Data Flow Graph卻是核心的技術,
考慮到Data Flow Graph中每個節點運算雖然仍不斷重複,
卻不再永遠簡單, 且衍伸出對於記憶體與計算時脈不同的需求,
原本GPU提供均質且大量的處理核心無法應付Data Flow Graph中異質的運算,
因此TPU引入了ASIC (Application-Specific Integrated Circuit)的概念,
簡單來說, TPU是一塊特殊設計的電路, 能夠快速進行某些deep learning的運算,
缺點就是, 因為硬體的特殊性, 你必須幫他編譯特殊的driver存取,
若是把TPU加入TensorFlow的分散式架構中,
整體平行化問題就變得更加困難,
這其中有三種運算單元: CPU, GPU, 和TPU,
至少兩種不同速度的溝通介面: 網路和PCIe,
主機板上的記憶題調配, GPU和TPU的內部記憶體配置,
這些問題才真正構成了TensorFlow的價值,
然而不幸的, 短期內我們只能架一個CPU+GPU的TensorFlow平台,
來猜猜Google的偉大計劃了...
應該是Google Alpha Go和李世石的圍棋對弈,
2016年3月, Alpha Go以4比1擊敗世界棋王, 贏得圍棋的桂冠,
這背後的技術就是deep learning, 也是建立於這次介紹的TensorFlow,

TensorFlow是一套開源平台, 由Google Brain團隊設計開發,
https://www.tensorflow.org/
在網路上有許多資源, 甚至有中文的社群:
http://www.tensorfly.cn/
相較於CUDA, TensorFlowr提供了一套資源調配技術,
可以分配運算資源到CPU或是 (藉由CUDA driver存取的) GPU中運算,
相對於傳統的deep learning運算方式, TensorFlow可以定義節點上更複雜的運算.
此時, 整個運算的框架, 更近似於傳統的HPC計算模式,
或者稱之為: Data Flow Graph
按照慣例, Google的開放資源永遠把最重要的技術隱藏起來,
其中, 第一點是TensorFlow的分散模式,
目前, TensorFlow仍只有單機模式, 調動的資源只有本機上的CPU和GPU,
可以視為一種單機內部自動資源配置的平行化架構,
然而, 對於一個複雜的運算而言, 例如圍棋,
如何協調單機和單機之間的資源配置, 是更困難的問題,
在一次Google研究員給的Talk中, 他們承認, 內部運行的是分散式架構,
只是這一部分的原始碼迄今尚未開放,
第二個隱藏起來的是稱為Tensor Processing Unit (TPU)的硬體,

然而, 這對於Data Flow Graph卻是核心的技術,
考慮到Data Flow Graph中每個節點運算雖然仍不斷重複,
卻不再永遠簡單, 且衍伸出對於記憶體與計算時脈不同的需求,
原本GPU提供均質且大量的處理核心無法應付Data Flow Graph中異質的運算,
因此TPU引入了ASIC (Application-Specific Integrated Circuit)的概念,
簡單來說, TPU是一塊特殊設計的電路, 能夠快速進行某些deep learning的運算,
缺點就是, 因為硬體的特殊性, 你必須幫他編譯特殊的driver存取,
若是把TPU加入TensorFlow的分散式架構中,
整體平行化問題就變得更加困難,
這其中有三種運算單元: CPU, GPU, 和TPU,
至少兩種不同速度的溝通介面: 網路和PCIe,
主機板上的記憶題調配, GPU和TPU的內部記憶體配置,
這些問題才真正構成了TensorFlow的價值,
然而不幸的, 短期內我們只能架一個CPU+GPU的TensorFlow平台,
來猜猜Google的偉大計劃了...


留言
張貼留言