LTE筆記: Intra-frequency and Equal Priority Cell Reselection
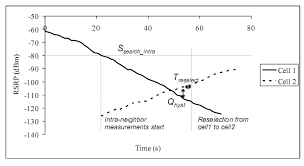
在 UE 移動時,將會定期得知連線 (serving) eNB的訊號強度,若是小於一定數值 (Ssearch_intra),則開始進行相鄰基地台 (target eNB) 的訊號強度量測 (Inter-neighbor measurement)。等到相鄰基地台的訊號強度比起服務 eNB 好上一定的數值 (Qhyst) 且持續一定時間 (Treselect),才進行換手。其中,我們可以把流程列如下圖。 圖一、Reselection的門檻與流程 在進行 Inter-neighbor measurement 後,UE 將根據 S-criteria 找出可用的 (suitable) 基地台,並根據 R-criteria 找出最佳的基地台,假如最佳的基地台不是服務的 (serving) eNB 則進行換手。 S-criteria 和 R-criteria 可以藉由調整參數變化,舉例來說,Qhyst 就是在 R-criteria 中的參數,用來提升服務的 (serving) eNB 的優先權,避免由於訊號的通道遮蔽效應 (shadowing effect) 或是衰減 (fading) 所造成的暫態訊號變化影響換手。Treselect 則要求此訊號差值維持一段時間,若是未達 Treselect 則重新計時,這是用來避免比如說 UE 在兩個 eNB 邊緣之間游移所造成的高頻率換手,或者,我們也稱之為乒乓效應 (ping-pong effect)。 Qhyst 和 Treselect 的設定,事實上是換手次數與 UE 訊號品質的權衡 (trade-off),較高的 Qhyst 與較長的 Treselect 將減少換手次數,但是 UE 必須忍受較低的訊號品質,且有因為訊號強度而斷線的風險。較低的 Qhyst 與較短的 Treselect 則提供較高的訊號品質,但是頻繁的換手,造成系統的負擔以及 UE 因為換手產生的延遲。