[WiFi] CAPWAP 介紹 (LWAP 和 WLC)
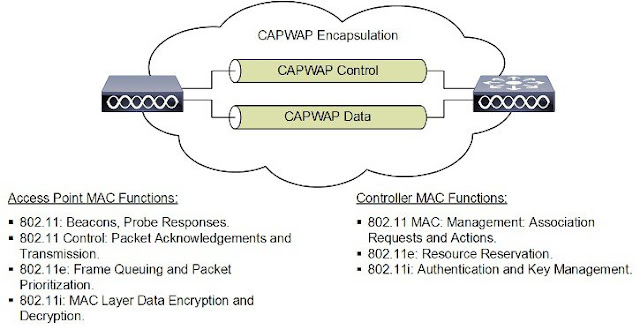
CAPWAP (Control and Provisioning of Wireless Access Points) 是一份由 Cisco 提出的協定, 主要用意在於提供佈建由 WiFi Controller 控管下的 WiFi 網路間的通訊, 考慮到 CAPWAP 實在有點龐雜, 這篇文章只會提及一些概念以及延伸的閱讀文件. 首先, 第一個概念是 CAPWAP 不是一份通訊協定, CAPWAP 的概念是透過多份 RFC 文件所完成, 其中最重要的是: RFC 5415 : Control And Provisioning of Wireless Access Points (CAPWAP) Protocol Specification RFC 5416 : Control and Provisioning of Wireless Access Points (CAPWAP) Protocol Binding for IEEE 802.11 其他還有一系列的相關文件圍繞 CAPWAP 的概念, 可以參考這一篇文章: http://what-when-how.com/deploying-and-troubleshooting-cisco-wireless-lan-controllers/overview-of-capwap-cisco-wireless-lan-controllers/